.png?width=900&height=487&name=Black%20And%20Beige%20Feminine%20How%20To%20Website%20Blog%20Banner%20(3).png)
Use the ChatGPT powered version in the GPT Store
Last updated February 2020. Originally published May 2015.
So, I admit it: When we started looking at our own blog traffic, we realized this was one of the most historically popular blog posts on the Seer domain. After a brief moment of reflection and a swell of enthusiasm for the ever-present greatness of the Screaming Frog SEO Spider, a tool that’s been a loyal companion in our technical SEO journey, we realized we were doing a disservice--both to our readers and to the many leaps forward from the great Screaming Frog.
Though this original guide was published in 2015, in the years since, Screaming Frog has evolved to offer a whole suite of new features and simplified steps to conduct technical audits, check a site’s health, or simply get a quick glimpse of info on a selection of URLs.
Below, you’ll find an updated guide to how SEOs, PPC professionals, and digital marketing experts can use the tool to streamline their workflow.
To get started, simply select what it is that you are looking to do:
Basic Crawling
- I want to crawl my entire site
- I want to crawl a single subdirectory
- I want to crawl a specific set of subdomains or subdirectories
- I want a list of all of the pages on my site
- I want a list of all of the pages in a specific subdirectory
- I want to find all of the subdomains on a site and verify internal links
- I want to crawl an e-commerce site or other large site
- I want to crawl a site hosted on an older server
- I want to crawl a site that requires cookies
- I want to crawl using a different user agent
- I want to crawl pages that require authentication
Internal Links
- I want information about all of the internal and external links on my site (anchor text, directives, links per page etc.)
- I want to find broken internal links on a page or site
- I want to find broken outbound links on a page or site (or all outbound links in general)
- I want to find links that are being redirected
- I am looking for internal linking opportunities
Site Content
- I want to identify pages with thin content
- I want a list of the image links on a particular page
- I want to find images that are missing alt text or images that have lengthy alt text
- I want to find every CSS file on my site
- I want to find every JavaScript file on my site
- I want to identify all of the jQuery plugins used on the site and what pages they are being used on
- I want to find where flash is embedded on-site
- I want to find any internal PDFs that are linked on-site
- I want to understand content segmentation within a site or group of pages
- I want to find pages that have social sharing buttons
- I want to find pages that are using iframes
- I want to find pages that contain embedded video or audio content
Meta Data and Directives
- I want to identify pages with lengthy page titles, meta descriptions, or URLs
- I want to find duplicate page titles, meta descriptions, or URLs
- I want to find duplicate content and/or URLs that need to be rewritten/redirected/canonicalized
- I want to identify all of the pages that include meta directives e.g.: nofollow/noindex/noodp/canonical etc.
- I want to verify that my robots.txt file is functioning as desired
- I want to find or verify Schema markup or other microdata on my site
Sitemap
- I want to create an XML Sitemap
- How to create an XML Sitemap by Uploading URLs
- I want to check my existing XML Sitemap
General Troubleshooting
- I want to identify why certain sections of my site aren't being indexed or aren’t ranking
- I want to check if my site migration/redesign was successful
- I want to find slow loading pages on my site
- I want to find malware or spam on my site
PPC & Analytics
- I want to verify that my Google Analytics code is on every page, or on a specific set of pages on my site
- I want to validate a list of PPC URLs in bulk
Scraping
- I want to scrape the meta data for a list of pages
- I want to scrape a site for all of the pages that contain a specific footprint
URL Rewriting
- I want to find and remove session id or other parameters from my crawled URLs
- I want to rewrite the crawled URLs (e.g: replace .com with .co.uk, or write all URLs in lowercase)
Keyword Research
- I want to know which pages my competitors value most
- I want to know what anchor text my competitors are using for internal linking
Link Building
- I want to analyze a list of prospective link locations
- I want to find broken links for outreach opportunities
- I want to verify my backlinks and view the anchor text
- I want to make sure that I'm not part of a link network
- I am in the process of cleaning up my backlinks and need to verify that links are being removed as requested
Bonus Round
Basic Crawling
How to crawl an entire site
When starting a crawl, it’s a good idea to take a moment and evaluate what kind of information you’re looking to get, how big the site is, and how much of the site you’ll need to crawl in order to access it all. Sometimes, with larger sites, it’s best to restrict the crawler to a sub-section of URLs to get a good representative sample of data. This keeps file sizes and data exports a bit more manageable. We go over this in further detail below. For crawling your entire site, including all subdomains, you’ll need to make some slight adjustments to the spider configuration to get started.
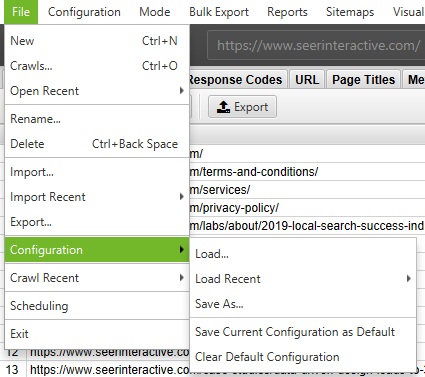
By default, Screaming Frog only crawls the subdomain that you enter. Any additional subdomains that the spider encounters will be viewed as external links. In order to crawl additional subdomains, you must change the settings in the Spider Configuration menu. By checking ‘Crawl All Subdomains’, you will ensure that the spider crawls any links that it encounters to other subdomains on your site.
Step 1:
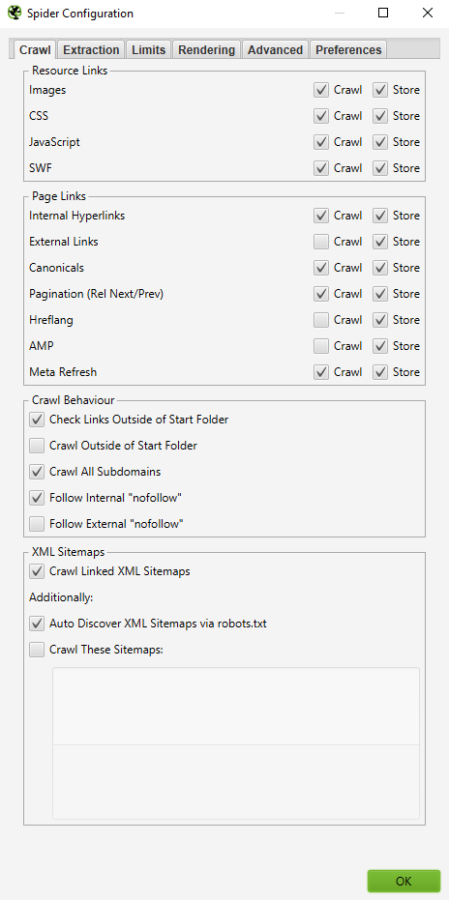
Step 2:
In addition, if you’re starting your crawl from a specific subfolder or subdirectory and still want Screaming Frog to crawl the whole site, check the box marked “Crawl Outside of Start Folder.”
By default, the SEO Spider is only set to crawl the subfolder or subdirectory you crawl from forwards. If you want to crawl the whole site and start from a specific subdirectory, be sure that the configuration is set to crawl outside the start folder.
Pro Tip:
To save time and disk space, be mindful of resources that you may not need in your crawl. Websites link to so much more than just pages. Uncheck Images, CSS, JavaScript, and SWF resources in order to reduce the size of the crawl.
How to crawl a single subdirectory
If you wish to limit your crawl to a single folder, simply enter the URL and press start without changing any of the default settings. If you've overwritten the original default settings, reset the default configuration within the 'File' menu.
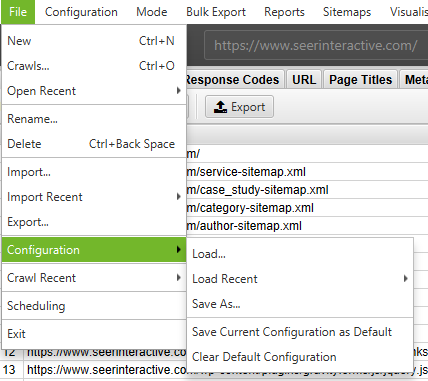
If you wish to start your crawl in a specific folder, but want to continue crawling to the rest of the subdomain, be sure to select ‘Crawl Outside Of Start Folder’ in the Spider Configuration settings before entering your specific starting URL.
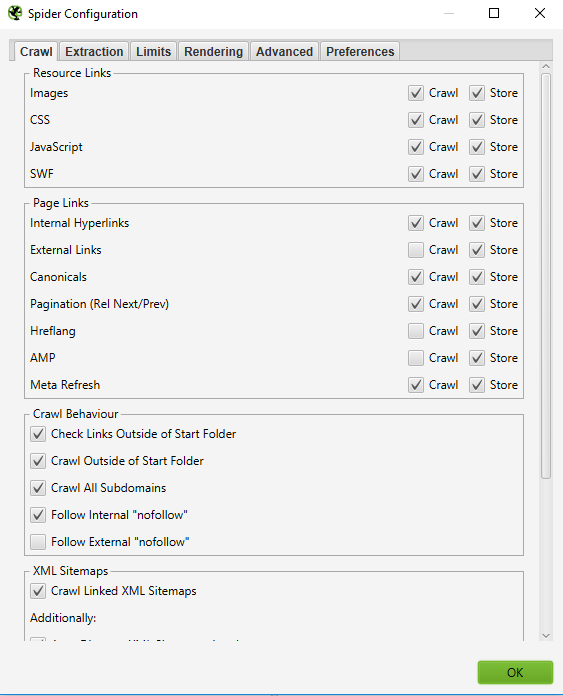
How to crawl a specific set of subdomains or subdirectories
If you wish to limit your crawl to a specific set of subdomains or subdirectories, you can use RegEx to set those rules in the Include or Exclude settings in the Configuration menu.
Exclusion:
In this example, we crawled every page on seerinteractive.com excluding the ‘about’ pages on every subdomain.
Step 1:
Go to Configuration > Exclude; use a wildcard regular expression to identify the URLs or parameters you want to exclude.
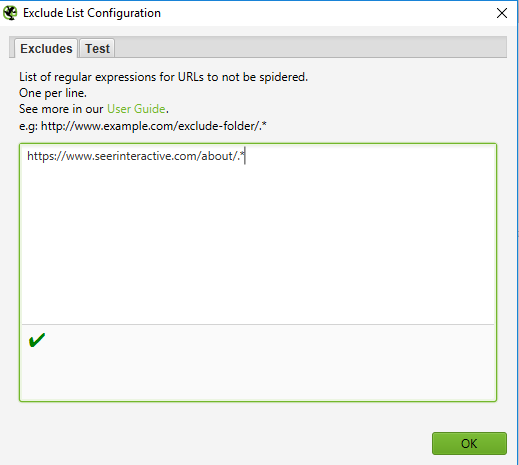
Step 2:
Test your regular expression to make sure it’s excluding the pages you expected to exclude before you start your crawl:
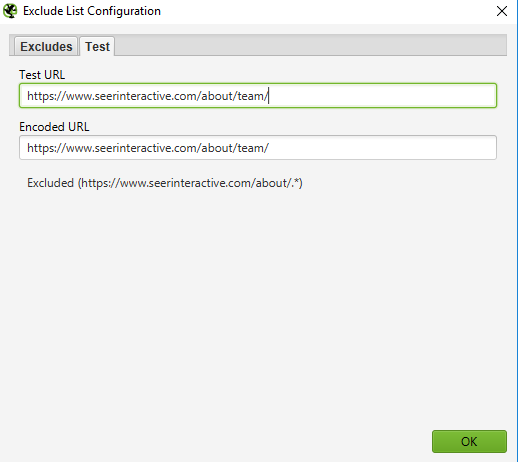
Inclusion:
In the example below, we only wanted to crawl the team subfolder on seerinteractive.com. Again, use the “Test” tab to test a few URLs and ensure the RegEx is appropriately configured for your inclusion rule.
This is a great way to crawl larger sites; in fact, Screaming Frog recommends this method if you need to divide and conquer a crawl for a bigger domain.
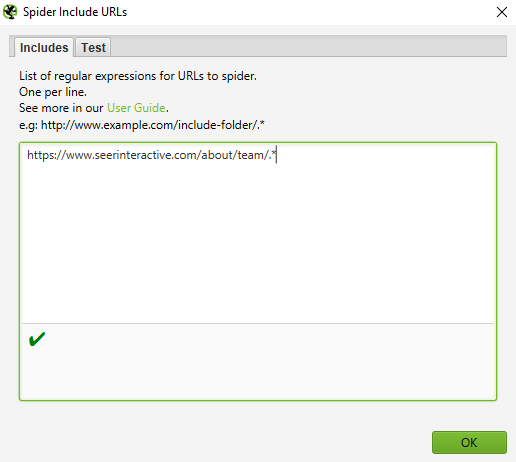
I want a list of all of the pages on my site
By default, Screaming Frog is set to crawl all images, JavaScript, CSS, and flash files that the spider encounters. To crawl HTML only, you’ll have to deselect ‘Check Images’, ‘Check CSS’, ‘Check JavaScript’ and ‘Check SWF’ in the Spider Configuration menu.
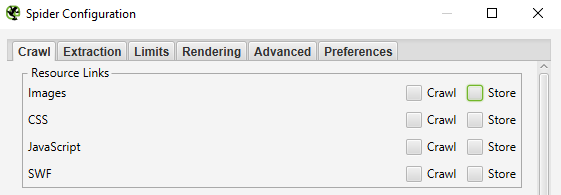
Running the spider with these settings unchecked will, in effect, provide you with a list of all of the pages on your site that have internal links pointing to them.
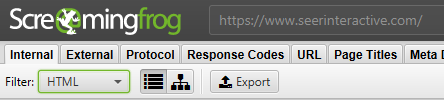
Once the crawl is finished, go to the ‘Internal’ tab and filter your results by ‘HTML’. Click ‘Export’, and you’ll have the full list in CSV format.
Pro Tip:
If you tend to use the same settings for each crawl, Screaming Frog now allows you to save your configuration settings:
I want a list of all of the pages in a specific subdirectory
In addition to de-selecting ‘Check Images’, ‘Check CSS’, ‘Check JavaScript’ and ‘Check SWF’, you’ll also want to de-select ‘Check Links Outside Folder’ in the Spider Configuration settings. Running the spider with these settings unchecked will, in effect, give you a list of all of the pages in your starting folder (as long as they are not orphaned pages).
How to find all of the subdomains on a site and verify internal links.
There are several different ways to find all of the subdomains on a site.
Method 1:
Use Screaming Frog to identify all subdomains on a given site. Navigate to Configuration > Spider, and ensure that “Crawl all Subdomains” is selected. Just like crawling your whole site above, this will help crawl any subdomain that is linked to within the site crawl. However, this will not find subdomains that are orphaned or unlinked.
Method 2:
Use Google to identify all indexed subdomains.
By using the Scraper Chrome extension and some advanced search operators, we can find all indexable subdomains for a given domain.
Step 1:
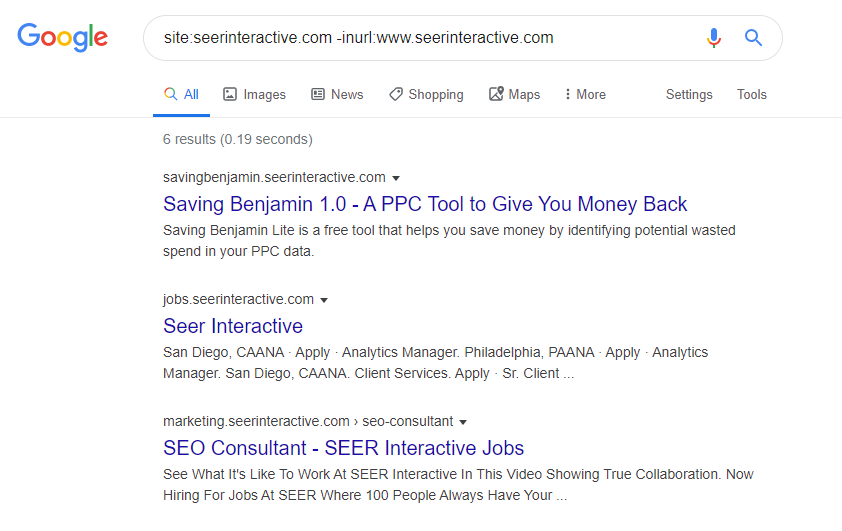
Start by using a site: search operator in Google to restrict results to your specific domain. Then, use the -inurl search operator to narrow the search results by removing the main domain. You should begin to see a list of subdomains that have been indexed in Google that do not contain the main domain.
Step 2:
Use the Scraper extension to extract all of the results into a Google Sheet. Simply right-click the URL in the SERP, click “Scrape Similar” and export to a Google Doc.
Step 3:
In your Google Doc, use the following function to trim the URL to the subdomain:
=LEFT(A2,SEARCH(“/”,A2,9))
Essentially, the formula above should help strip off any subdirectories, pages, or file names at the end of a site. This formula essentially tells sheets or Excel to return what is to the left of the trailing slash. The start number of 9 is significant because we are asking it to start looking for a trailing slash after the 9th character. This accounts for the protocol: https://, which is 8 characters long.
De-duplicate the list, and upload the list into Screaming Frog in List Mode--you can manually paste the list of domains, use the paste function, or upload a CSV.
Method 3:
Enter the root domain URL into tools that help you look for sites that might exist on the same IP or search engines designed especially to search for subdomains. Create a free account to login and export a list of subdomains. Then, upload the list to Screaming Frog using List Mode.
Once the spider has finished running, you’ll be able to see status codes, as well as any links on the subdomain homepages, anchor text, and duplicate page titles among other things.
How to crawl an e-commerce site or other large site
Screaming Frog was not originally built to crawl hundreds of thousands of pages, but thanks to some upgrades, it’s getting closer every day.
The newest version of Screaming Frog has been updated to rely on database storage for crawls. In version 11.0, Screaming Frog allowed users to opt to save all data to disk in a database rather than just keep it in RAM. This opened up the possibility of crawling very large sites for the first time.
In version 12.0, the crawler automatically saves crawls to the database. This allows them to be accessed and opened using “File > Crawls” in the top-level menu--in case you panic and wonder where the open command went!
While using database crawls helps Screaming Frog better manage larger crawls, it’s certainly not the only way to crawl a large site.
First, you can increase the memory allocation of the spider.
Second, you can break down the crawl by subdirectory or only crawl certain parts of the site using your Include/Exclude settings.
Third, you can choose not to crawl images, JavaScript, CSS, and flash. By deselecting these options in the Configuration menu, you can save memory by crawling HTML only.
Pro Tip:
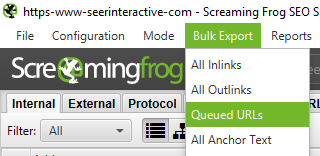
Until recently, the Screaming Frog SEO Spider might have paused or crashed when crawling a large site. Now, with database storage as the default setting, you can recover crawls to pick up where you left off. Additionally, you can also access queued URLs. This may give you insight into any additional parameters or rules you may want to exclude in order to crawl a large site.
How to crawl a site hosted on an older server -- or how to crawl a site without crashing it
In some cases, older servers may not be able to handle the default number of URL requests per second. In fact, we recommend including a limit on the number of URLs to crawl per second to be respectful of a site’s server just in case. It’s best to let a client know when you’re planning on crawling a site just in case they might have protections in place against unknown User Agents. On one hand, they may need to whitelist your IP or User Agent before you crawl the site. The worst-case scenario may be that you send too many requests to the server and inadvertently crash the site.
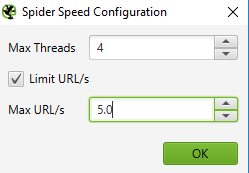
To change your crawl speed, choose ‘Speed’ in the Configuration menu, and in the pop-up window, select the maximum number of threads that should run concurrently. From this menu, you can also choose the maximum number of URLs requested per second.
Pro Tip:
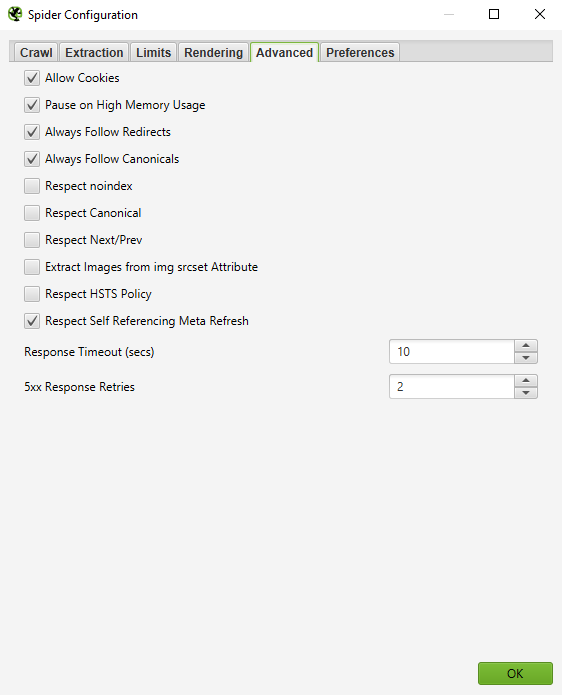
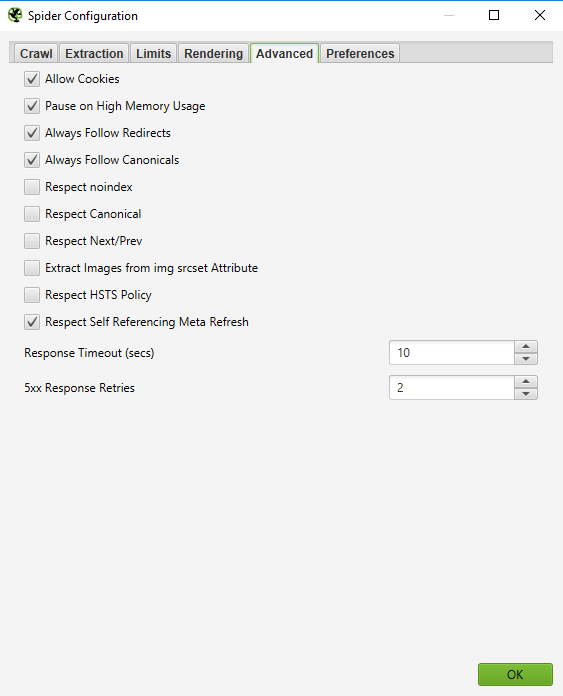
If you find that your crawl is resulting in a lot of server errors, go to the 'Advanced' tab in the Spider Configuration menu, and increase the value of the 'Response Timeout' and of the '5xx Response Retries' to get better results.
How to crawl a site that requires cookies
Although search bots don't accept cookies, if you are crawling a site and need to allow cookies, simply select 'Allow Cookies' in the 'Advanced' tab of the Spider Configuration menu.
How to crawl using a different user-agent
To crawl using a different user agent, select ‘User Agent’ in the ‘Configuration’ menu, then select a search bot from the drop-down or type in your desired user agent strings.
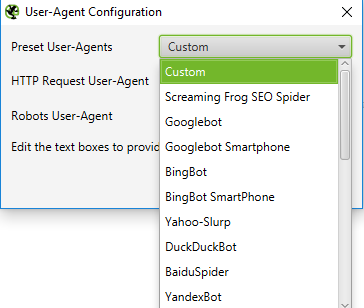
As Google is now mobile-first, try crawling the site as Googlebot Smartphone, or modify the User-Agent to be a spoof of Googlebot Smartphone. This is important for two different reasons:
- Crawling the site mimicking the Googlebot Smartphone user agent may help determine any issues that Google is having when crawling and rendering your site’s content.
- Using a modified version of the Googlebot Smartphone user agent will help you distinguish between your crawls and Google’s crawls when analyzing server logs.
How to crawl pages that require authentication
When the Screaming Frog spider comes across a page that is password-protected, a pop-up box will appear, in which you can enter the required username and password.
Forms-Based authentication is a very powerful feature and may require JavaScript rendering in order to effectively work. Note: Forms-Based authentication should be used sparingly, and only by advanced users. The crawler is programmed to click every link on a page, so that could potentially result in links to log you out, create posts, or even delete data.
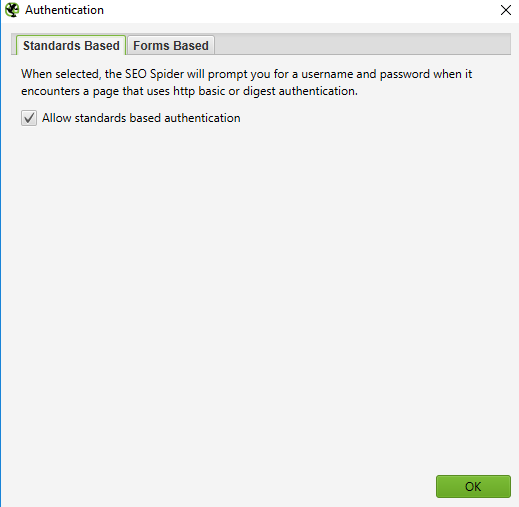
To manage authentication, navigate to Configuration > Authentication.
In order to turn off authentication requests, deselect ‘Standards Based Authentication’ in the ‘Authentication’ window from the Configuration menu.
Internal Links
I want information about all of the internal and external links on my site (anchor text, directives, links per page etc.)
If you do not need to check the images, JavaScript, flash or CSS on the site, de-select these options in the Spider Configuration menu to save processing time and memory.
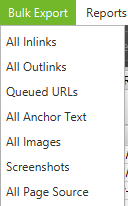
Once the spider has finished crawling, use the Bulk Export menu to export a CSV of ‘All Links’. This will provide you with all of the link locations, as well as the corresponding anchor text, directives, etc.
All inlinks can be a big report. Be mindful of this when exporting. For a large site, this export can sometimes take minutes to run.
For a quick tally of the number of links on each page, go to the ‘Internal’ tab and sort by ‘Outlinks’. Anything over 100, might need to be reviewed.

Need something a little more processed? Check out this tutorial on calculating the importance of internal linking spearheaded by Allison Hahn and Zaine Clark.
How to find broken internal links on a page or site
If you do not need to check the images, JavaScript, flash, or CSS of the site, de-select these options in the Spider Configuration menu to save processing time and memory.
Once the spider has finished crawling, sort the 'Internal' tab results by ‘Status Code’. Any 404's, 301's or other status codes will be easily viewable.
Upon clicking on any individual URL in the crawl results, you’ll see information change in the bottom window of the program. By clicking on the 'In Links' tab in the bottom window, you’ll find a list of pages that are linking to the selected URL, as well as anchor text and directives used on those links. You can use this feature to identify pages where internal links need to be updated.
To export the full list of pages that include broken or redirected links, choose ‘Redirection (3xx) In Links’ or ‘Client Error (4xx) In Links’ or ‘Server Error (5xx) In Links’ in the ‘Advanced Export’ menu, and you’ll get a CSV export of the data.
To export the full list of pages that include broken or redirected links, visit the Bulk Export menu. Scroll down to response codes, and look at the following reports:
- No Response Inlinks
- Redirection (3xx) Inlinks
- Redirection (JavaScript) Inlinks
- Redirection (Meta Refresh) Inlinks
- Client Error (4xx) Inlinks
- Server Error (5xx) Inlinks
Reviewing all of these reports should give us an adequate representation of what internal links should be updated to ensure they point to the canonical version of the URL and efficiently distribute link equity.
How to find broken outbound links on a page or site (or all outbound links in general)
After de-selecting ‘Check Images’, ‘Check CSS’, ‘Check JavaScript’ and ‘Check SWF’ in the Spider Configuration settings, make sure that ‘Check External Links’ remains selected.
After the spider is finished crawling, click on the ‘External’ tab in the top window, sort by ‘Status Code’ and you’ll easily be able to find URLs with status codes other than 200. Upon clicking on any individual URL in the crawl results and then clicking on the ‘In Links’ tab in the bottom window, you’ll find a list of pages that are pointing to the selected URL. You can use this feature to identify pages where outbound links need to be updated.
To export your full list of outbound links, click ‘External Links’ on the Bulk Export tab.
For a complete listing of all the locations and anchor text of outbound links, select ‘All Outlinks’ in the ‘Bulk Export’ menu. The All Outlinks report will include outbound links to your subdomains as well; if you want to exclude your domain, lean on the “External Links” report referenced above.
How to find links that are being redirected
After the spider has finished crawling, select the ‘Response Codes’ tab from the main UI, and filter by Status Code. Because Screaming Frog uses Regular Expressions for search, submit the following criteria as a filter: 301|302|307. This should give you a pretty solid list of all links that came back with some sort of redirect, whether the content was permanently moved, found and redirected, or temporarily redirected due to HSTS settings (this is the likely cause of 307 redirects in Screaming Frog). Sort by ‘Status Code’, and you’ll be able to break the results down by type. Click on the ‘In Links’ tab in the bottom window to view all of the pages where the redirecting link is used.
If you export directly from this tab, you will only see the data that is shown in the top window (original URL, status code, and where it redirects to).
To export the full list of pages that include redirected links, you will have to choose ‘Redirection (3xx) In Links’ in the ‘Advanced Export’ menu. This will return a CSV that includes the location of all your redirected links. To show internal redirects only, filter the ‘Destination’ column in the CSV to include only your domain.
ProTip:
Use a VLOOKUP between the 2 export files above to match the Source and Destination columns with the final URL location.
Sample formula:
=VLOOKUP([@Destination],’response_codes_redirection_(3xx).csv’!$A$3:$F$50,6,FALSE)
(Where ‘response_codes_redirection_(3xx).csv’ is the CSV file that contains the redirect URLs and ‘50’ is the number of rows in that file.)
Need to find and fix redirect chains? @dan_shure gives the breakdown on how to do it here.
I am looking for internal linking opportunities
Internal linking opportunities can yield massive ROI--especially when you’re being strategic about the distribution of PageRank & link equity, keyword rankings, and keyword-rich anchors.
Our go-to resource for internal linking opportunities comes down to the impressive Power BI dashboard created by our very own Allison Hahn and Zaine Clark. Learn more here.
Site Content
How to identify pages with thin content
After the spider has finished crawling, go to the ‘Internal’ tab, filter by HTML, then scroll to the right to the ‘Word Count’ column. Sort the ‘Word Count’ column from low to high to find pages with low text content. You can drag and drop the ‘Word Count’ column to the left to better match the low word count values to the appropriate URLs. Click ‘Export’ in the ‘Internal’ tab if you prefer to manipulate the data in a CSV instead.
Pro Tip for E-commerce Sites:
While the word count method above will quantify the actual text on the page, there’s still no way to tell if the text found is just product names or if the text is in a keyword-optimized copy block. To figure out the word count of your text blocks, use ImportXML2 by @iamchrisle to scrape the text blocks on any list of pages, then count the characters from there. If xPath queries aren’t your strong suit, the xPath Helper or Xpather Chrome extension does a pretty solid job at figuring out the xPath for you. Obviously, you can also use these scraped text blocks to begin to understand the overall word usage on the site in question, but that, my friends, is another post…
I want a list of the image links on a particular page
If you’ve already crawled a whole site or subfolder, simply select the page in the top window, then click on ‘Image Info’ tab in the bottom window to view all of the images that were found on that page. The images will be listed in the ‘To’ column.
Pro Tip:
Right-click on any entry in the bottom window to copy or open a URL.
Alternatively, you can also view the images on a single page by crawling just that URL. Make sure that your crawl depth is set to ‘1’ in the Spider Configuration settings, then once the page is crawled, click on the ‘Images’ tab, and you’ll see any images that the spider found.
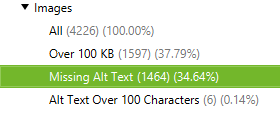
How to find images that are missing alt text or images that have lengthy alt text
First, you’ll want to make sure that ‘Check Images’ is selected in the Spider Configuration menu. After the spider has finished crawling, go to the ‘Images’ tab and filter by ‘Missing Alt Text’ or ‘Alt Text Over 100 Characters’. You can find the pages where any image is located by clicking on the ‘Image Info’ tab in the bottom window. The pages will be listed in the ‘From’ column.
Finally, if you prefer a CSV, use the ‘Bulk Export’ menu to export ‘All Images’ or ‘Images Missing Alt Text Inlinks’ to see the full list of images, where they are located and any associated alt text or issues with alt text.
Additionally, use the right sidebar to navigate to the Images section of the crawl; here, you can easily export a list of all images missing alt text.
How to find every CSS file on my site
In the Spider Configuration menu, select ‘Crawl’ and ‘Store’ CSS before crawling, then when the crawl is finished, filter the results in the ‘Internal’ tab by ‘CSS’.

How to find every JavaScript file on my site
In the Spider Configuration menu, select ‘Check JavaScript’ before crawling, then when the crawl is finished, filter the results in the ‘Internal’ tab by ‘JavaScript’.
How to identify all of the jQuery plugins used on the site and what pages they are being used on
First, make sure that ‘Check JavaScript’ is selected in the Spider Configuration menu. After the spider has finished crawling, filter the ‘Internal’ tab by ‘JavaScript’, then search for ‘jquery’. This will provide you with a list of plugin files. Sort the list by the ‘Address’ for easier viewing if needed, then view ‘InLinks’ in the bottom window or export the data into a CSV to find the pages where the file is used. These will be in the ‘From’ column.
Alternatively, you can use the ‘Advanced Export’ menu to export a CSV of ‘All Links’ and filter the ‘Destination’ column to show only URLs with ‘jquery’.
Pro Tip:
Not all jQuery plugins are bad for SEO. If you see that a site uses jQuery, the best practice is to make sure that the content that you want to be indexed is included in the page source and is served when the page is loaded, not afterward. If you are still unsure, Google the plugin for more information on how it works.
How to find where flash is embedded on-site
In the Spider Configuration menu, select ‘Check SWF’ before crawling, then when the crawl is finished, filter the results in the ‘Internal’ tab by ‘Flash’.
This is increasingly important to find and identify content that is being delivered by Flash and suggest alternate code for the content. Chrome is in the process of deprecating Flash across the board; this is really something that should be used to highlight if there are issues with critical content and Flash on a site.
NB: This method will only find .SWF files that are linked on a page. If the flash is pulled in through JavaScript, you’ll need to use a custom filter.
How to find any internal PDFs that are linked on-site
After the spider has finished crawling, filter the results in the ‘Internal’ tab by ‘PDF’.
How to understand content segmentation within a site or group of pages
If you want to find pages on your site that contain a specific type of content, set a custom filter for an HTML footprint that is unique to that page. This needs to be set *before* running the spider.
How to find pages that have social sharing buttons
To find pages that contain social sharing buttons, you’ll need to set a custom filter before running the spider. To set a custom filter, go into the Configuration menu and click ‘Custom’. From there, enter any snippet of code from the page source.

In the example above, I wanted to find pages that contain a Facebook ‘like’ button, so I created a filter for facebook.com/plugins/like.php.
How to find pages that are using iframes
To find pages that use iframes, set a custom filter for <
How to find pages that contain embedded video or audio content
To find pages that contain embedded video or audio content, set a custom filter for a snippet of the embed code for Youtube, or any other media player that is used on the site.

Meta Data and Directives
How to identify pages with lengthy page titles, meta descriptions, or URLs
After the spider has finished crawling, go to the ‘Page Titles’ tab and filter by ‘Over 60 Characters’ to see the page titles that are too long. You can do the same in the ‘Meta Description’ tab or in the ‘URI’ tab.

How to find duplicate page titles, meta descriptions, or URLs
After the spider has finished crawling, go to the ‘Page Titles’ tab, then filter by ‘Duplicate’. You can do the same thing in the ‘Meta Description’ or ‘URI’ tabs.

How to find duplicate content and/or URLs that need to be rewritten/redirected/canonicalized
After the spider has finished crawling, go to the ‘URI’ tab, then filter by ‘Underscores’, ‘Uppercase’ or ‘Non ASCII Characters’ to view URLs that could potentially be rewritten to a more standard structure. Filter by ‘Duplicate’ and you’ll see all pages that have multiple URL versions. Filter by ‘Parameters’ and you’ll see URLs that include parameters.
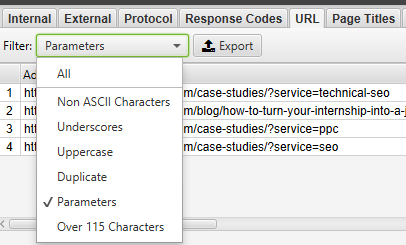
Additionally, if you go to the 'Internal' tab, filter by 'HTML', and scroll the to 'Hash' column on the far right, you'll see a unique series of letters and numbers for every page. If you click 'Export', you can use conditional formatting in Excel to highlight the duplicated values in this column, ultimately showing you pages that are identical and need to be addressed.
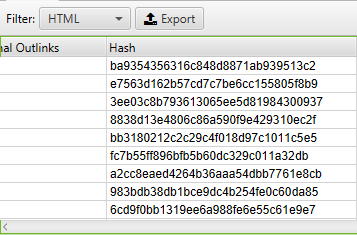
How to identify all of the pages that include meta directives e.g.: nofollow/noindex/noodp/canonical etc.
After the spider has finished crawling, click on the ‘Directives’ tab. To see the type of directive, simply scroll to the right to see which columns are filled, or use the filter to find any of the following tags:
- index
- noindex
- follow
- nofollow
- noarchive
- nosnippet
- noodp
- noydir
- noimageindex
- notranslate
- unavailable_after
- refresh
How to verify that my robots.txt file is functioning as desired
By default, Screaming Frog will comply with robots.txt. As a priority, it will follow directives made specifically for the Screaming Frog user agent. If there are no directives specifically for the Screaming Frog user agent, then the spider will follow any directives for Googlebot, and if there are no specific directives for Googlebot, the spider will follow global directives for all user agents. The spider will only follow one set of directives, so if there are rules set specifically for Screaming Frog it will only follow those rules, and not the rules for Googlebot or any global rules. If you wish to block certain parts of the site from the spider, use the regular robots.txt syntax with the user agent ‘Screaming Frog SEO Spider’. If you wish to ignore robots.txt, simply select that option in the Spider Configuration settings.
Configuration > Robots.txt > Settings
How to find or verify Schema markup or other microdata on my site
To find every page that contains Schema markup or any other microdata, you need to use custom filters. Simply click on ‘Custom’ → ‘Search’ in the Configuration Menu and enter the footprint that you are looking for.
To find every page that contains Schema markup, simply add the following snippet of code to a custom filter: itemtype=http://schema.org
To find a specific type of markup, you’ll have to be more specific. For example, using a custom filter for ‹span itemprop=”ratingValue”› will get you all of the pages that contain Schema markup for ratings.
As of Screaming Frog 11.0, the SEO spider also offers us the ability to crawl, extract, and validate structured data directly from the crawl. Validate any JSON-LD, Microdata, or RDFa structured data against the guidelines from Schema.org and specifications from Google in real-time as you crawl. To access the structured data validation tools, select the options under “Config > Spider > Advanced.”
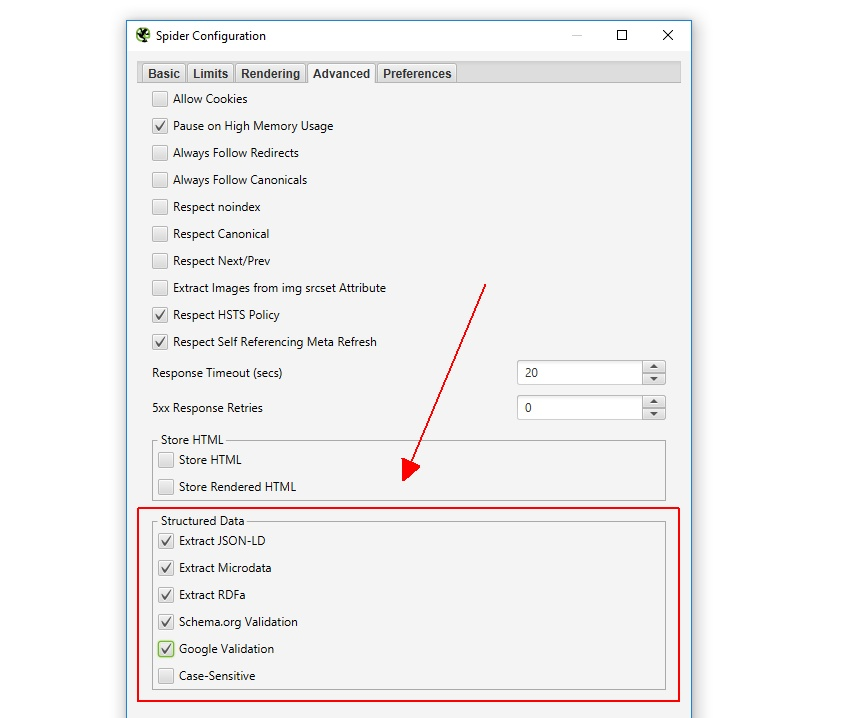
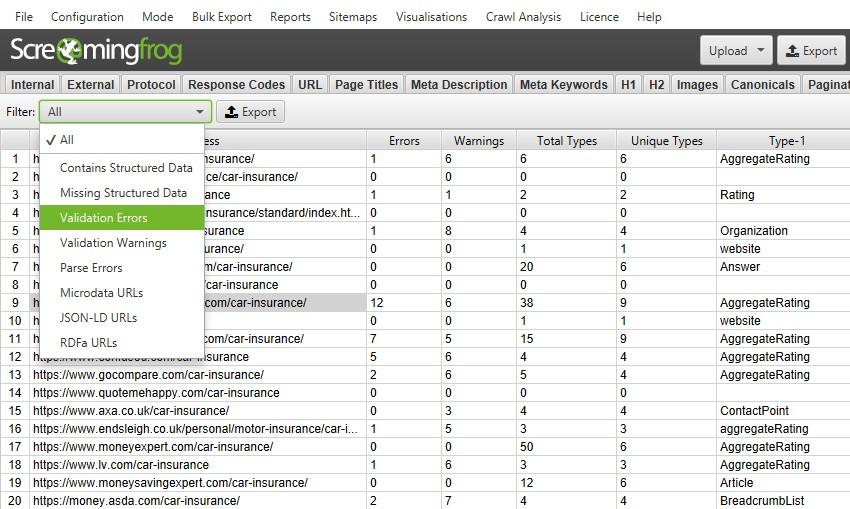
There is now a Structured Data tab within the main interface that will allow you to toggle between pages that contain structured data, that are missing structured data, and that may have validation errors or warnings:
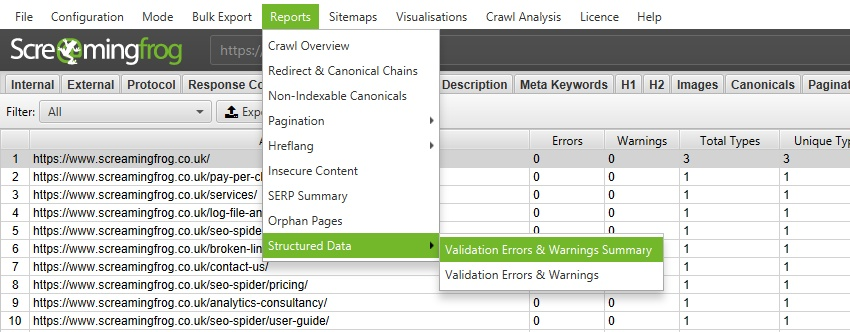
You can also bulk export issues with structured data by visiting “Reports > Structured Data > Validation Errors & Warnings.”
Sitemap
How to create an XML Sitemap
After the spider has finished crawling your site, click on the ‘Siteamps’ menu and select ‘XML Sitemap’.

Once you have opened the XML sitemap configuration settings, you are able to include or exclude pages by response codes, last modified, priority, change frequency, images etc. By default, Screaming Frog only includes 2xx URLs but it’s a good rule of thumb to always double-check.
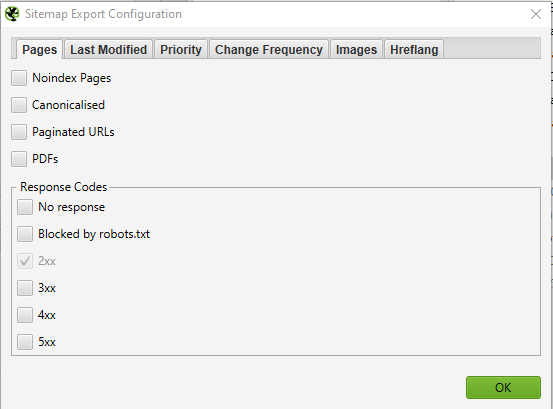
Ideally, your XML sitemap should only include a 200 status, single, preferred (canonical) version of each URL, without parameters or other duplicating factors. Once any changes have been made, hit OK. The XML sitemap file will download to your device and allow you to edit the naming convention however you’d like.
Creating an XML Sitemap By Uploading URLs
You can also create an XML sitemap by uploading URLs from an existing file or pasting manually into Screaming Frog.
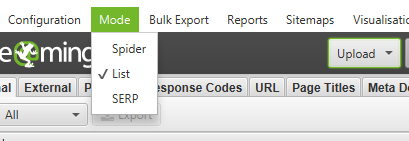
Change the ‘Mode’ from Spider to List and click on the Upload dropdown to select either option.
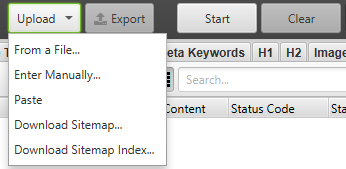
Hit the Start button and Screaming Frog will crawl the uploaded URLs. Once the URLs are crawled, you will follow the same process that is listed above.
How to check my existing XML Sitemap
You can easily download your existing XML sitemap or sitemap index to check for any errors or crawl discrepancies.
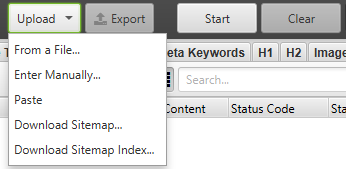
Go to the ‘Mode’ menu in Screaming Frog and select ‘List’. Then, click ‘Upload’ at the top of the screen, choose either Download Sitemap or Download Sitemap Index, enter the sitemap URL, and start the crawl. Once the spider has finished crawling, you’ll be able to find any redirects, 404 errors, duplicated URLs and more. You can easily export and of the errors identified.
Identifying Missing Pages within XML Sitemap
You can configure your crawl settings to discover and compare the URLs within your XML sitemaps to the URLs within your site crawl.
Go to ‘Configuration’ -> ‘Spider’ in the main navigation and at the bottom, there are a few options for XML sitemaps - Auto discover XML sitemaps through your robots.txt file or manually enter the XML sitemap link into the box. *Important note - if your robots.txt file does not contain proper destination links to all XML sitemaps you want to be crawled, you should manually enter them.
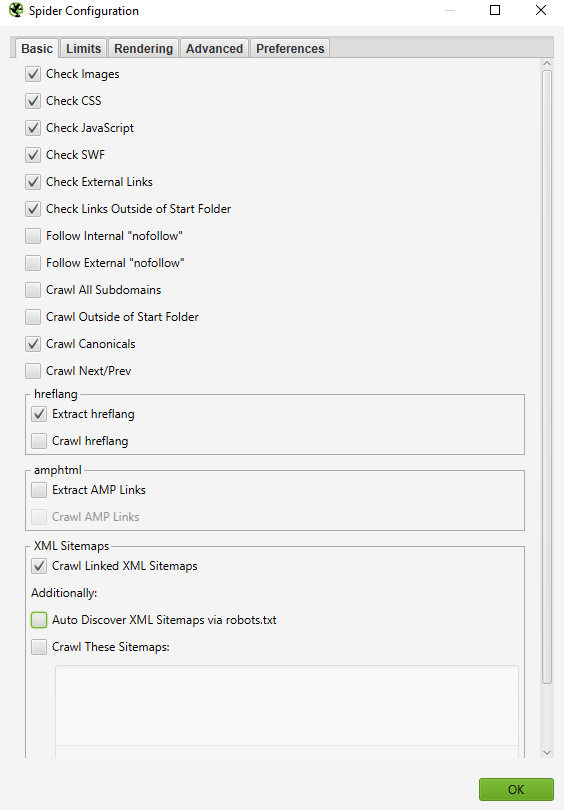
Once you’ve updated your XML Sitemap crawl settings, go to ‘Crawl Analysis’ in the navigation then click ‘Configure’ and ensure the Sitemaps button is ticked. You’ll want to run your full site crawl first, then navigate back to ‘Crawl Analysis’ and hit Start.
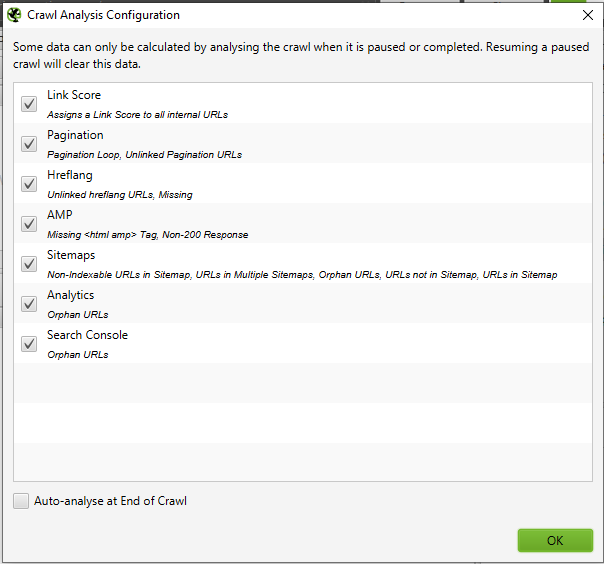
Once the Crawl Analysis is complete, you’ll be able to see any crawl discrepancies, such as URLs that were detected within the full site crawl that are missing from the XML sitemap.
General Troubleshooting
How to identify why certain sections of my site aren't being indexed or aren’t ranking
Wondering why certain pages aren’t being indexed? First, make sure that they weren’t accidentally put into the robots.txt or tagged as noindex. Next, you’ll want to make sure that spiders can reach the pages by checking your internal links. A page that is not internally linked somewhere on your site is often referred to as an Orphaned Page.
In order to identify any orphaned pages, complete the following steps:
- Go to ‘Configuration’ -> ‘Spider’ in the main navigation and at the bottom there are a few options for XML sitemaps - Auto discover XML sitemaps through your robots.txt file or manually enter the XML sitemap link into the box. *Important note - if your robots.txt file does not contain proper destination links to all XML sitemap you want crawled, you should manually enter them.
- Go to ‘Configuration → API Access’ → ‘Google Analytics’ - using the API you can pull in analytics data for a specific account and view. To find orphan pages from organic search, make sure to segment by ‘Organic Traffic’
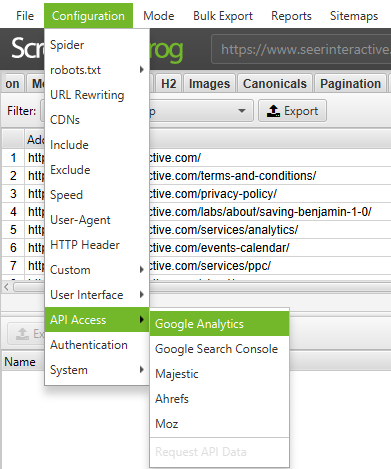
- You can also go to General → ‘Crawl New URLs Discovered In Google Analytics’ if you would like the URLs discovered in GA to be included within your full site crawl. If this is not enabled, you will only be able to view any new URLs pulled in from GA within the Orphaned Pages report.
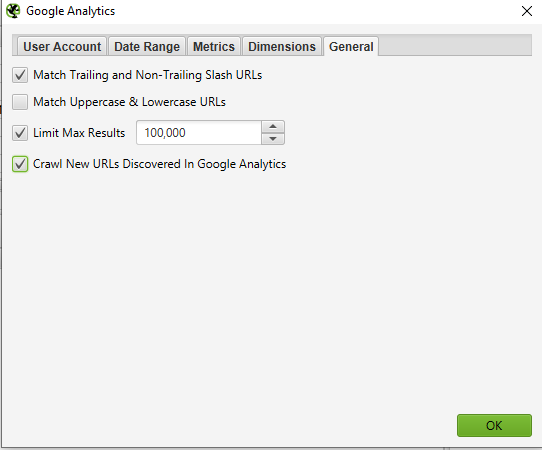
- Go to ‘Configuration → API Access’ → ‘Google Search Console’ - using the API you can pull in GSC data for a specific account and view. To find orphan pages you can look for URLs receiving clicks and impressions that are not included in your crawl.
- You can also go to General → ‘Crawl New URLs Discovered In Google Search Console’ if you would like the URLs discovered in GSC to be included within your full site crawl. If this is not enabled, you will only be able to view any new URLs pulled in from GSC within the Orphaned Pages report.
- Crawl the entire website. Once the crawl is completed, go to ‘Crawl Analysis --> Start’ and wait for it to finish.
- View orphaned URLs within each of the tabs or bulk export all orphaned URLs by going to Reports → Orphan Pages
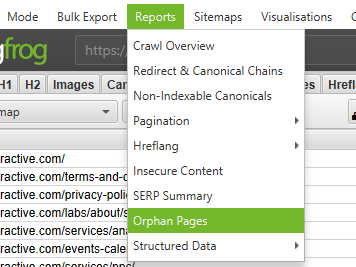
If you do not have access to Google Analytics or GSC you can export the list of internal URLs as a .CSV file, using the ‘HTML’ filter in the ‘Internal’ tab.
Open up the CSV file, and in a second sheet, paste the list of URLs that aren’t being indexed or aren’t ranking well. Use a VLOOKUP to see if the URLs in your list on the second sheet were found in the crawl.
How to check if my site migration/redesign was successful
@ipullrank has an excellent Whiteboard Friday on this topic, but the general idea is that you can use Screaming Frog to check whether or not old URLs are being redirected by using the ‘List’ mode to check status codes. If the old URLs are throwing 404’s, then you’ll know which URLs still need to be redirected.
How to find slow-loading pages on my site
After the spider has finished crawling, go to the 'Response Codes' tab and sort by the 'Response Time' column from high to low to find pages that may be suffering from a slow loading speed.

How to find malware or spam on my site
First, you’ll need to identify the footprint of the malware or the spam. Next, in the Configuration menu, click on ‘Custom’ → ‘Search’ and enter the footprint that you are looking for.
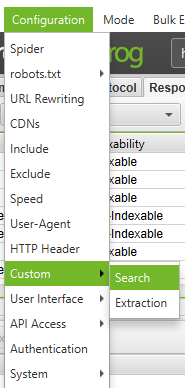
You can enter up to 10 different footprints per crawl. Finally, press OK and proceed with crawling the site or list of pages.
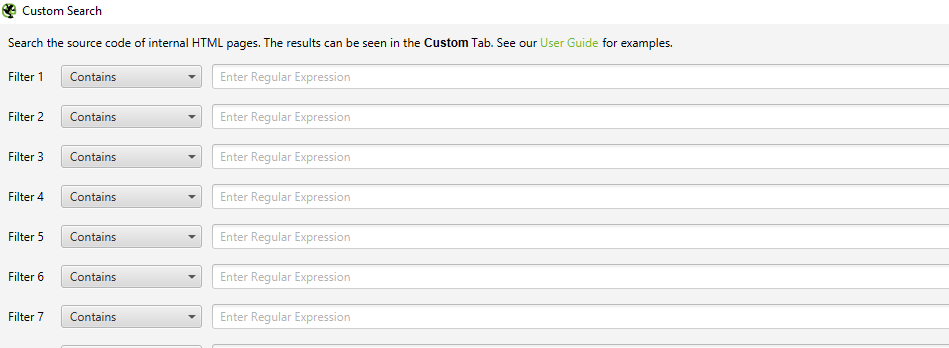
When the spider has finished crawling, select the ‘Custom’ tab in the top window to view all of the pages that contain your footprint. If you entered more than one custom filter, you can view each one by changing the filter on the results.
PPC & Analytics
How to verify that my Google Analytics code is on every page, or on a specific set of pages on my site
SEER alum @RachaelGerson wrote a killer post on this subject: Use Screaming Frog to Verify Google Analytics Code. Check it out!
How to validate a list of PPC URLs in bulk
Save your list in .txt or .csv format, then change your ‘Mode’ settings to ‘List’.
Next, select your file to upload, and press ‘Start’ or paste your list manually into Screaming Frog. See the status code of each page by looking at the ‘Internal’ tab.
To check if your pages contain your GA code, check out this post on using custom filters to verify Google Analytics code by @RachaelGerson.
Scraping
How to scrape the metadata for a list of pages
So, you’ve harvested a bunch of URLs, but you need more information about them? Set your mode to ‘List’, then upload your list of URLs in .txt or .csv format. After the spider is done, you’ll be able to see status codes, outbound links, word counts, and of course, metadata for each page in your list.
How to scrape a site for all of the pages that contain a specific footprint
First, you’ll need to identify the footprint. Next, in the Configuration menu, click on ‘Custom’ → ‘Search’ or ‘Extraction’ and enter the footprint that you are looking for.
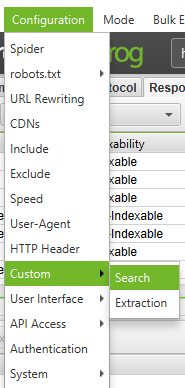
You can enter up to 10 different footprints per crawl. Finally, press OK and proceed with crawling the site or list of pages. In the example below, I wanted to find all of the pages that say ‘Please Call’ in the pricing section, so I found and copied the HTML code from the page source.
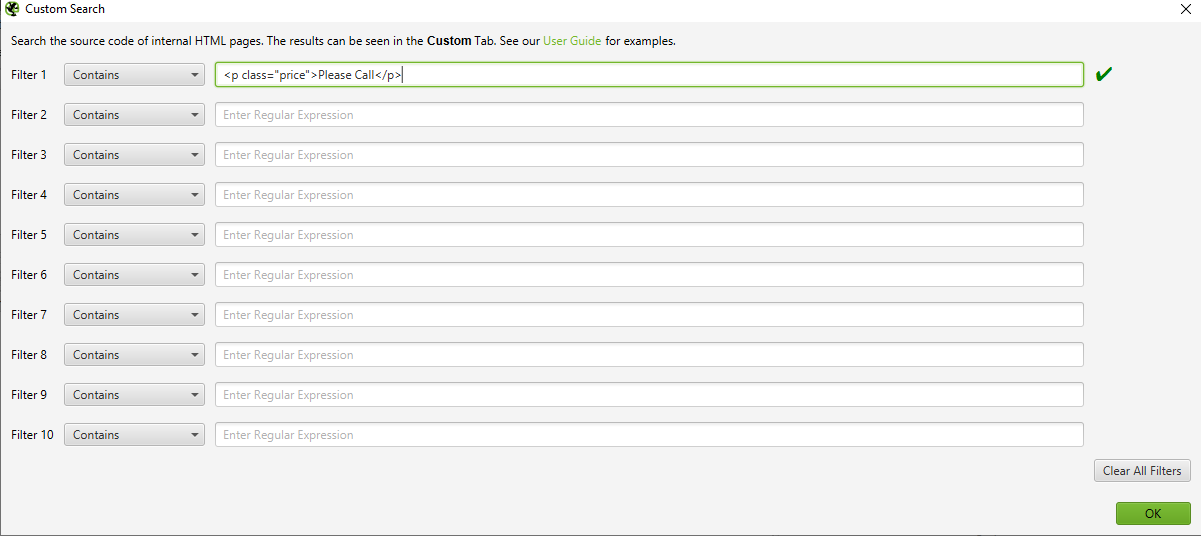
When the spider has finished crawling, select the ‘Custom’ tab in the top window to view all of the pages that contain your footprint. If you entered more than one custom filter, you can view each one by changing the filter on the results.
Below are some additional common footprints you can scrape from websites that may be useful for your SEO audits:
- http://schema\.org - Find pages containing schema.org
- youtube.com/embed/|youtu.be|<video|player.vimeo.com/video/|wistia.(com|net)/embed|sproutvideo.com/embed/|view.vzaar.com|dailymotion.com/embed/|players.brightcove.net/|play.vidyard.com/|kaltura.com/(p|kwidget)/ - Find pages containing video content
Pro Tip:
If you are pulling product data from a client site, you could save yourself some time by asking the client to pull the data directly from their database. The method above is meant for sites that you don’t have direct access to.
URL Rewriting
How to find and remove session id or other parameters from my crawled URLs
To identify URLs with session ids or other parameters, simply crawl your site with the default settings. When the spider is finished, click on the ‘URI’ tab and filter to ‘Parameters’ to view all of the URLs that include parameters.
To remove parameters from being shown for the URLs that you crawl, select ‘URL Rewriting’ in the configuration menu, then in the ‘Remove Parameters’ tab, click ‘Add’ to add any parameters that you want to be removed from the URLs, and press ‘OK.’ You’ll have to run the spider again with these settings in order for the rewriting to occur.
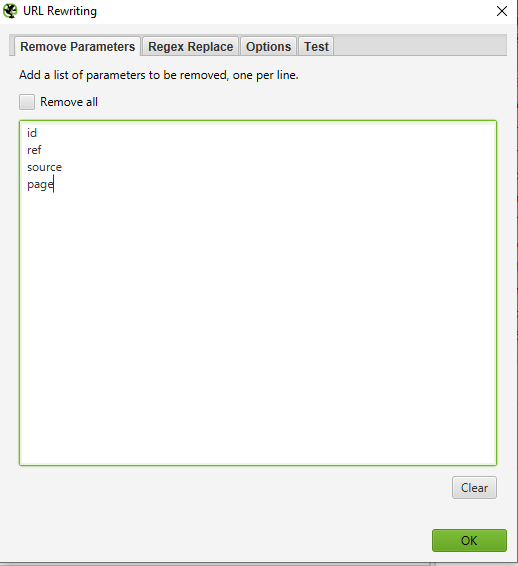
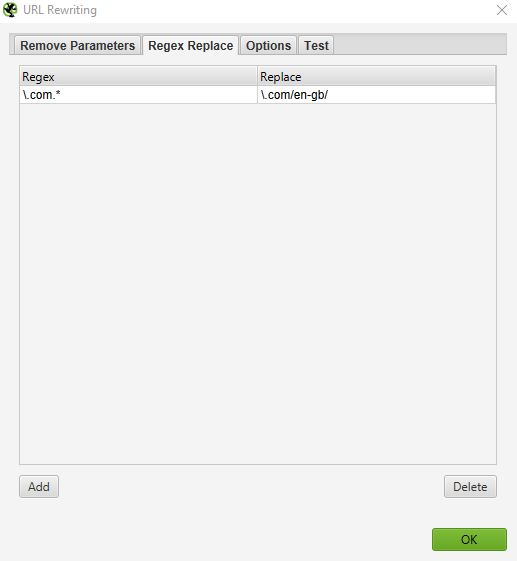
How to rewrite the crawled URLs (e.g: replace .com with .co.uk, or write all URLs in lowercase)
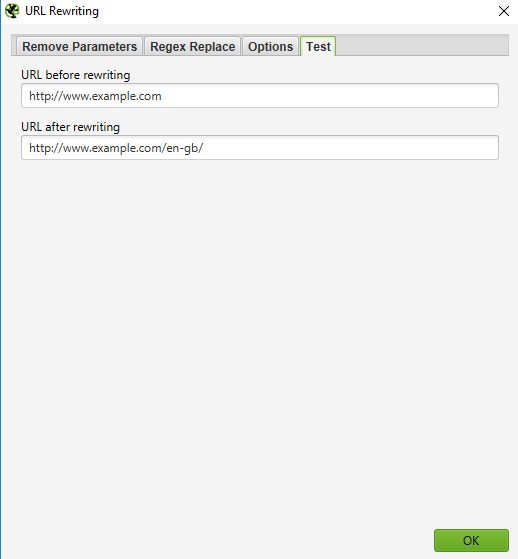
To rewrite any URL that you crawl, select ‘URL Rewriting’ in the Configuration menu, then in the ‘Regex Replace’ tab, click ‘Add’ to add the RegEx for what you want to replace.
Once you’ve added all of the desired rules, you can test your rules in the ‘Test’ tab by entering a test URL in the space labeled ‘URL before rewriting’. The ‘URL after rewriting’ will be updated automatically according to your rules.
If you wish to set a rule that all URLs are returned in lowercase, simply select ‘Lowercase discovered URLs’ in the ‘Options’ tab. This will remove any duplication by capitalized URLs in the crawl.
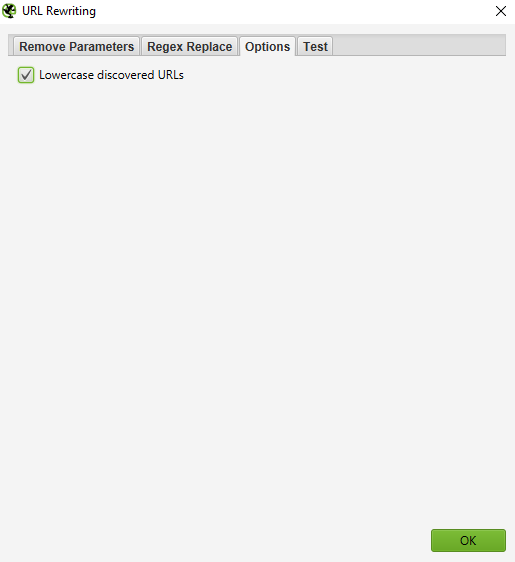
Remember that you’ll have to actually run the spider with these settings in order for the URL rewriting to occur.
Keyword Research
How to know which pages my competitors value most
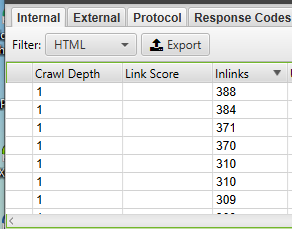
Generally speaking, competitors will try to spread link popularity and drive traffic to their most valuable pages by linking to them internally. Any SEO-minded competitor will probably also link to important pages from their company blog. Find your competitor’s prized pages by crawling their site, then sorting the ‘Internal’ tab by the ‘Inlinks’ column from highest to lowest, to see which pages have the most internal links.
To view pages linked from your competitor’s blog, deselect ‘Check links outside folder’ in the Spider Configuration menu and crawl the blog folder/subdomain. Then, in the ‘External’ tab, filter your results using a search for the URL of the main domain. Scroll to the far right and sort the list by the ‘Inlinks’ column to see which pages are linked most often.

Pro Tip:
Drag and drop columns to the left or right to improve your view of the data.
How to know what anchor text my competitors are using for internal linking
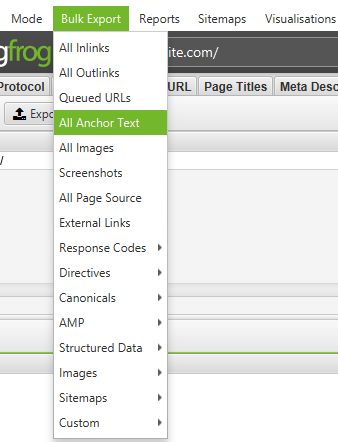
In the ‘Bulk Export’ menu, select ‘All Anchor Text’ to export a CSV containing all of the anchor text on the site, where it is used and what it’s linked to.
How to know which meta keywords (if any) my competitors have added to their pages
After the spider has finished running, look at the ‘Meta Keywords’ tab to see any meta keywords found for each page. Sort by the ‘Meta Keyword 1’ column to alphabetize the list and visually separate the blank entries, or simply export the whole list.
Link Building
How to analyze a list of prospective link locations
If you’ve scraped or otherwise come up with a list of URLs that needs to be vetted, you can upload and crawl them in ‘List’ mode to gather more information about the pages. When the spider is finished crawling, check for status codes in the ‘Response Codes’ tab, and review outbound links, link types, anchor text, and nofollow directives in the ‘Outlinks’ tab in the bottom window. This will give you an idea of what kinds of sites those pages link to and how. To review the ‘Outlinks’ tab, be sure that your URL of interest is selected in the top window.
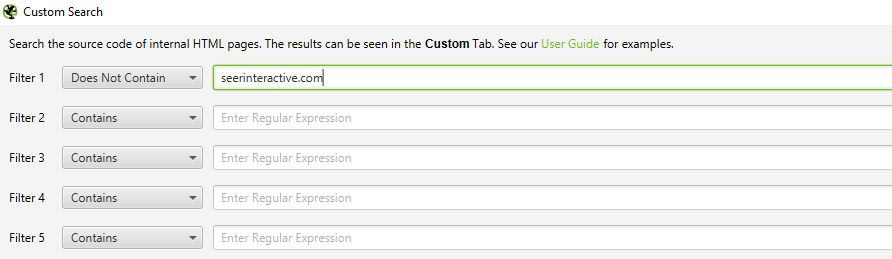
Of course, you’ll want to use a custom filter to determine whether or not those pages are linking to you already.
You can also export the full list of our links by clicking on ‘All Outlinks’ in the ‘Bulk Export Menu’. This will not only provide you with the links going to external sites, but it will also show all internal links on the individual pages in your list.
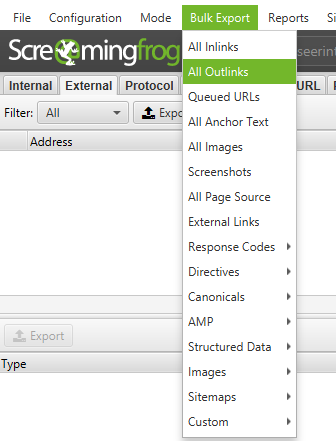
For more great ideas for link building, check out these two awesome posts on link reclamation and using Link Prospector with Screaming Frog by SEER’s own @EthanLyon and @JHTScherck.
How to find broken links for outreach opportunities
So, you found a site that you would like a link from? Use Screaming Frog to find broken links on the desired page or on the site as a whole, then contact the site owner, suggesting your site as a replacement for the broken link where applicable, or just offer the broken link as a token of good will.
How to verify my backlinks and view the anchor text
Upload your list of backlinks and run the spider in ‘List’ mode. Then, export the full list of outbound links by clicking on ‘All Out Links’ in the ‘Advanced Export Menu’. This will provide you with the URLs and anchor text/alt text for all links on those pages. You can then use a filter on the ‘Destination’ column of the CSV to determine if your site is linked and what anchor text/alt text is included.
@JustinRBriggs has a nice tidbit on checking infographic backlinks with Screaming Frog. Check out the other 17 link building tools that he mentioned, too.
How to make sure that I'm not part of a link network
Want to figure out if a group of sites are linking to each other? Check out this tutorial on visualizing link networks using Screaming Frog and Fusion Tables by @EthanLyon.
I am in the process of cleaning up my backlinks and need to verify that links are being removed as requested
Set a custom filter that contains your root domain URL, then upload your list of backlinks and run the spider in ‘List’ mode. When the spider has finished crawling, select the ‘Custom’ tab to view all of the pages that are still linking to you.
Bonus Round
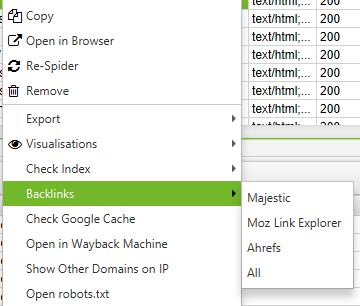
Did you know that by right-clicking on any URL in the top window of your results, you could do any of the following?
- Copy or open the URL
- Re-crawl the URL or remove it from your crawl
- Export URL Info, In Links, Out Links, or Image Info for that page
- Check indexation of the page in Google, Bing and Yahoo
- Check backlinks of the page in Majestic, OSE, Ahrefs and Blekko
- Look at the cached version/cache date of the page
- See older versions of the page
- Validate the HTML of the page
- Open robots.txt for the domain where the page is located
- Search for other domains on the same IP
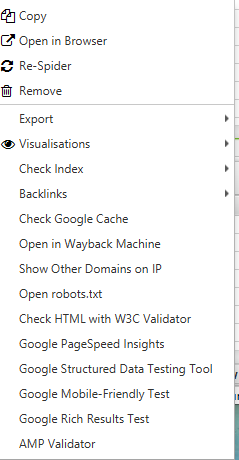
Likewise, in the bottom window, with a right-click, you can:
- Copy or open the URL in the 'To' for 'From' column for the selected row
How to Edit Meta Data
SERP Mode allows you to preview SERP snippets by device to visually show how your meta data will appear in search results.
- Upload URLs, titles and meta descriptions into Screaming Frog using a .CSV or Excel document
- If you already ran a crawl for your site you can export URLs by going to ‘Reports → SERP Summary’. This will easily format the URLs and meta you want to reupload and edit.
- Mode → SERP → Upload File
- Edit the meta data within Screaming Frog
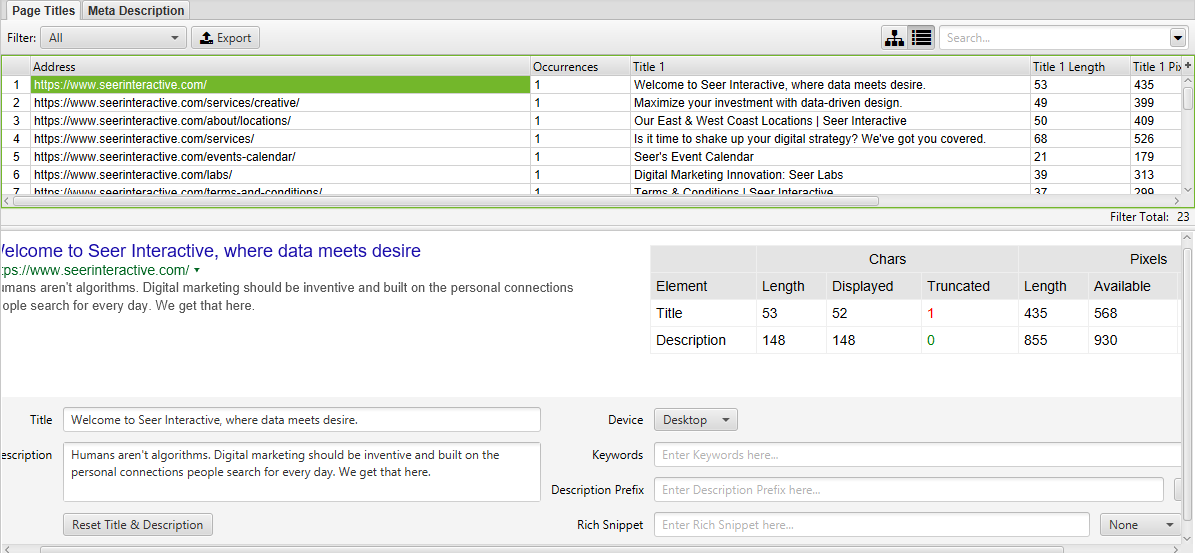
- Bulk export updated meta data to send directly to developers to update
How to a Crawl JavaScript Site
It’s becoming more common for websites to be built using JavaScript frameworks like Angular, React, etc. Google strongly recommends using a rendering solution as Googlebot still struggles to crawl javascript content. If you’ve identified a website built using javascript, follow the below instructions to crawl the website.
- ‘Configuration → Spider → Rendering → JavaScript
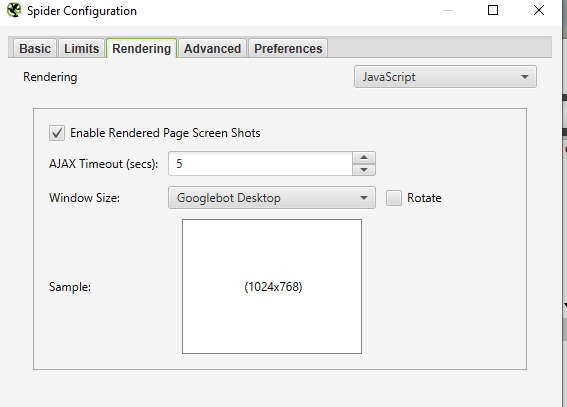
- Change rendering preferences depending on what you’re looking for. You can adjust the timeout time, window size (mobile, tablet, desktop, etc)
- Hit OK and crawl the website
Within the bottom navigation, click on the Rendered Page tab to view how the page is being rendered. If your page is not being rendered properly, check for blocked resources or extend the timeout limit within the configuration settings. If neither option helps solve the how your page is rendering, there may be a larger issue to uncover.
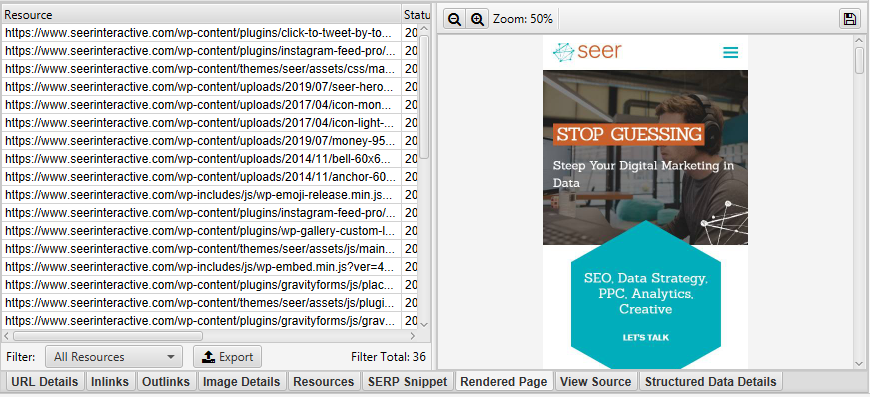
You can view and bulk export any blocked resources that may be impacting crawling and rendering of your website by going to ‘Bulk Export’ → ‘Response Codes’
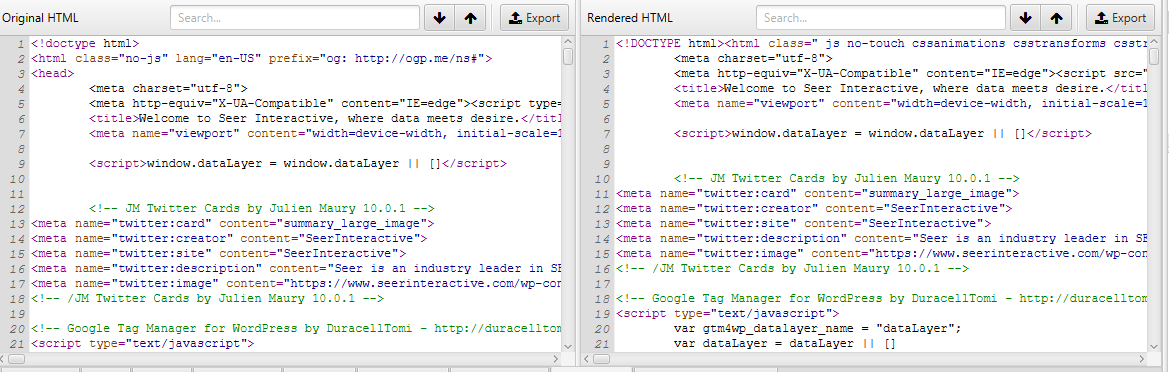
View Original HTML and Rendered HTML
If you’d like to compare the raw HTML and rendered HTML to identify any discrepancies or ensure important content is located within the DOM, go to ‘Configuration’ → ’Spider’ --> ‘Advanced’ and hit store HTML & store rendered HTML.
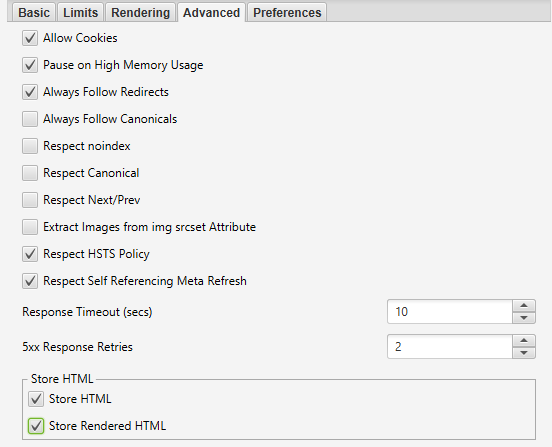
Within the bottom window, you will be able to see the raw and rendered HTML. This can help identify issues with how your content is being rendered and viewed by crawlers.
Tell us what else you've discovered!
Final Remarks
In closing, I hope that this guide gives you a better idea of what Screaming Frog can do for you. It has saved me countless hours, so I hope that it helps you, too!
By the way, I am not affiliated with Screaming Frog; I just think that it's an awesome tool.
Still nerding out on technical SEO?
Check out our open positions.
For more SEO tutorials and the latest digital marketing updates, subscribe to the Seer newsletter below.