Nobody knows technical fouls better than Ron Artest, period. You can probably make an argument for Rasheed or Malone but no one took it to another level than Mr. World Peace himself. Although I am nowhere near as experienced with Mr. Artest in terms of technical fouls, I am part of SEER’s technical SEO team and I’m here to address one of the most common technical SEO issues that we run into while doing architecture audits, canonicals and duplicate content. So without further ado, “T him up ref!”

Canonicals & Parametered URLs
Canonicals are used to clean up duplicate content and prioritize which URL should show up in the search results. Instead of splitting your link equity across URLs with similar or duplicate content, the canonical tag tells search engines, “I know the content on these two URLs are identical or very similar, but I want you to serve this one up in the search results” This helps bots crawl through your site more efficiently, gives the searcher the best result all while preserving your crawl budget.
When you see parametered URLs ranking in search results, this is most likely a canonical issue. Parametered URLs, or what I like to call “dirty” URLs are URLs that are used for campaign tracking purposes or more commonly, are filters created when selecting different options on websites.
For instance, here is an example of a parametered URL for a floor rug that is green, made by a specific brand, under $100 and kid friendly.
http://www.example.com/rugs/floorrugs.html?brand_name=21688&nav_color=19342&nav_price=11334&nav_style=11609
Because there are probably more people that aren’t searching for something that specific, the search volume does not justify having its own clean URL.
In order to remove these results from the search results, I would add a canonical tag that points to its non parametered version, and I’d also recommend adding a noindex, follow meta robots tag. Additionally, if those filters are written in HTML, I would also suggest disallowing them in your robots.txt file to preserve your crawl budget.
Check your parameters in GWMT
Checking your parameters in Google Webmaster Tools is a MUST when evaluating your site for duplicate content. In Google Webmaster Tools, under the “crawl” tab navigate to the “URL Parameters” section.
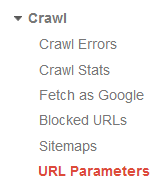
There you will find parameters that Google has crawled while giving you the option to change how Google monitors the URL. Depending on the parameter and whether or not it changes the content on the page, you can tell Google whether or not to crawl or ignore those parameters or let Googlebot decide.
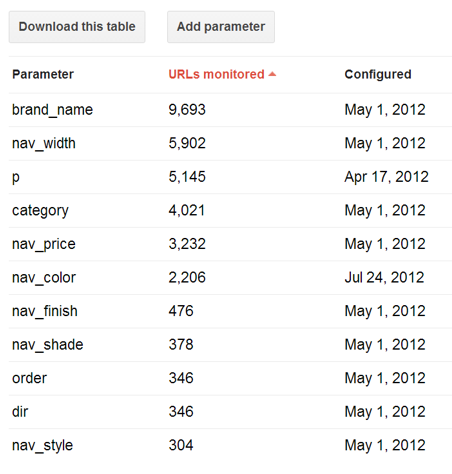
All duplicate content of this nature should have canonical tags or implemented to consolidate inbound link value.
Paginated URLs & Rel=prev/next
I cringe whenever I see paginated URLs in search results. Why? Because no is searching for the nth page of a blog when that page’s content changes as frequently as you update your blog. Rel=Prev/Next was introduced to send signals to search engines that a piece of content that exceeds one page, is in the same series as each other. Below is an example of correct rel=prev/next implementation on example.com/blog/my-new-puppy?p=2
<link rel="next" href=" www. example.com/blog/my-new-puppy?p=3
<link rel="prev" href=" www. example.com/blog/my-new-puppy
One common mistake I see is rel=prev/next tags implemented on posts that are posted before or after each other. Here is an example of incorrect rel=prev/next on the example URL:
www.example.com/blog/my-new-puppy
<link rel="prev" href=" www.example.com/blog/i-think-im-going-to-buy-a-dog
<link rel="next" href=" www.example.com/blog/first-week-of-a-dog-owner
Although you may have written these posts one after each other, rel=prev/next should only be used on pieces of content that exceed one page.
Mobile Pages showing in SERPs
I often see mobile sites appearing in desktop search results as shown below.
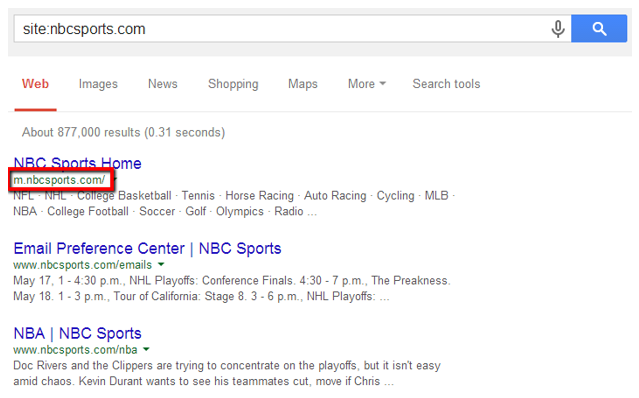
Because mobile sites should only be served on mobile devices, having incorrect mobile markup may send users to a mobile result, providing a bad desktop experience.
In order for search engines to better understand the relationship between pages on this site and pages on the desktop site, two pieces of markup will need to be added.
First, on the mobile site, a canonical tag will need to be implemented on mobile pages, pointing back to their corresponding desktop URLs.
Then, on desktop pages, a rel=“alternate” tag should be added to the <head> of each page, pointing back to its mobile version. Alternately, the rel=“alternate” tag can be added into the XML sitemap of the desktop site to indicate the relationship between the pages. (The canonical tag must be added to the mobile site in either situation.)
Common Duplicate Content Issues
Finally, below are the most common duplicate content issues to look for.
www. and non www. versions of URLs
When URLs are accessible through both:
www.example.com
example.com
Create a rewrite rule to remove or keep the www. It doesn’t matter if you do one or the other, as long as you keep it consistent across the site.
Trailing slash
When URLs are accessible through both:
Create a rewrite rule to remove or keep the trailing slash. It doesn’t matter if you do one or the other, as long as you keep it consistent across the site.
/index URLs
When /index URLs are serving the same content as non /index URLs:
Create a rewrite rule to redirect all /index versions of URLs to the clean, non-/index versions of the URL.
Upper and lowercase URLs
When URLs are showing duplicate content through both:
Create a rewrite rule to standardize all URLs to lowercase.
Thank you for reading and huge shout out to Aichlee Bushnell for teaching me the ropes! 

