
Key Takeaway: In this presentation, "A Novel Approach to Scraping Websites", Rob Ousbey walks through tactics to scrape websites that don’t have an API or export feature, or on sites that require some kind of authentication.
Simple Code to Scrape Websites
Scraping websites doesn’t have to be a specialty in SEO. In his technical presentation, Rob walks through a simple way to scrap sites (G2, Google, etc.).
You are able to crawl sites from your desktop using tools like Screaming Frog or from servers like STAT and Moz.
When working with large data scrapes, you can run into a few issues: authentication, and rate limiting.
Starting with G2, you can tackle scraping this site in three ways:
- Using the JS code Rob provides
- Ask someone who knows how to code JS
- Learn how to code JS
Sites scraping themselves - trick the site into thinking they have the JS built on them
I'm not doing anything blackhat, I'm just using computers to do the things I would have been doing anyway. Just much, much faster.
Rob walks through three options:
- Option 1: One-off scrapes: Chrome Dev Tools > Console Tab > Use JQuery
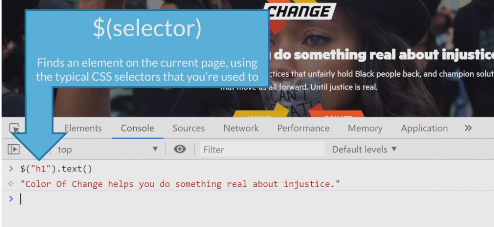
- Option 2: To run code multiple times, use JavaScript bookmarklets and store them as bookmarks to run whenever you need to
- Option 2: To run code multiple times, use JavaScript bookmarklets and store them as bookmarks to run whenever you need to
- Option 3: Online JavaScript file storage

- Host your code online (Dropbox, etc.)
- Create a bookmarklet that only imports code
- Include the bookmarklet on the page by creating a new script element
Use .get requests, .find and get HTML back -- paste the following code into dev tools:

Populates tables, 10 requests happen and the data is re-written back into the table.
Need to use the HTML function to write.
- Inspect code for yourself or install bookmarklet: ousbey.com/mozcon
- Chapter 2: Making Google become the scraper
- How many pages does Google have indexed of each folder on the site? This can be helpful for competitive insights.
- Using site search > exclude folders we already know about > replace input with output > run your booklet on google.com
- setTimeout(function,delay)
- Chapter 3: WebDev -- LightHouse report for any URL
- The page is doing an AJAX request - look in Chrome Dev Tools and is making a cross--domain request.
- Go into MozPro > look at Keyword data/rankings > SERP analysis > include lighthouse metrics in the report > additional columns and cells are added into the report
Sign-up for our newsletter to receive full access into our MozCon 2020 recap:


